

Bibliographic Networks: A Python Tutorial
Networks can provide significant measures to identify data driven patterns and dependencies. Though, given a data file it can be difficult to discern how one may approach creating such a network. In this tutorial, we will use a bibliographic data file downloaded from a query search in Scopus to walk through the process of cleaning the data file, writing a python script to parse the data into nodes and edges, computing graphical measures using NetworkX, and creating an interactive network display using HoloViews.
We tried out multiple Python libraries for ease of use and efficiency before landing on this combination. Building a network was more intuitive in NetworkX than iGraph. However, it took several minutes to render our large graph and a interaction was sticky. Pyvis was easy to build a network with and can be expanded to incorporate more advanced NetworkX functionality with only a couply lines of code. However it still took a long time to render, with slow manipulation. Holoviews, which runs on top of the native Python visualization library Bokeh, enables NetworkX to render quickly, with versitile manipulation. The graphs are produced in HTML and JavaScript for easy integration into webpages.
About Colaboratory
While we originally developed this script in a local notebook, we found that running it through Google’s cloud-based Jupyter notebook environment Colaboratory is a smoother option, particularly for nacent coders. We encountered version conflicts between the dependencies when setting up a local notebook environment that were bipassed in Colab. Colaboratory allows you to use and share Jupyter notebooks from your browser, without having to download, install, or run anything on your own computer. Notebooks can be saved to Google Drive, Github or downloaded locally. This code contains OAuth2 functionality to access data from Google Drive, with a link to instructions for access from Github. A single line of code adapts the script render in Colab.
To open the notebook in Colab, click on the notebook from the repository list. GitHub will open a preview, click this icon from the top of the notebook to open directly in Colaboratory. (If the preview doesn’t load, you may have to disable your ad blocker.) Alternatively, you can clone or download this repository and put in Google Drive. Google Drive will recognize the .ipynb notebook file format and give you the option to open in Colaboratory.

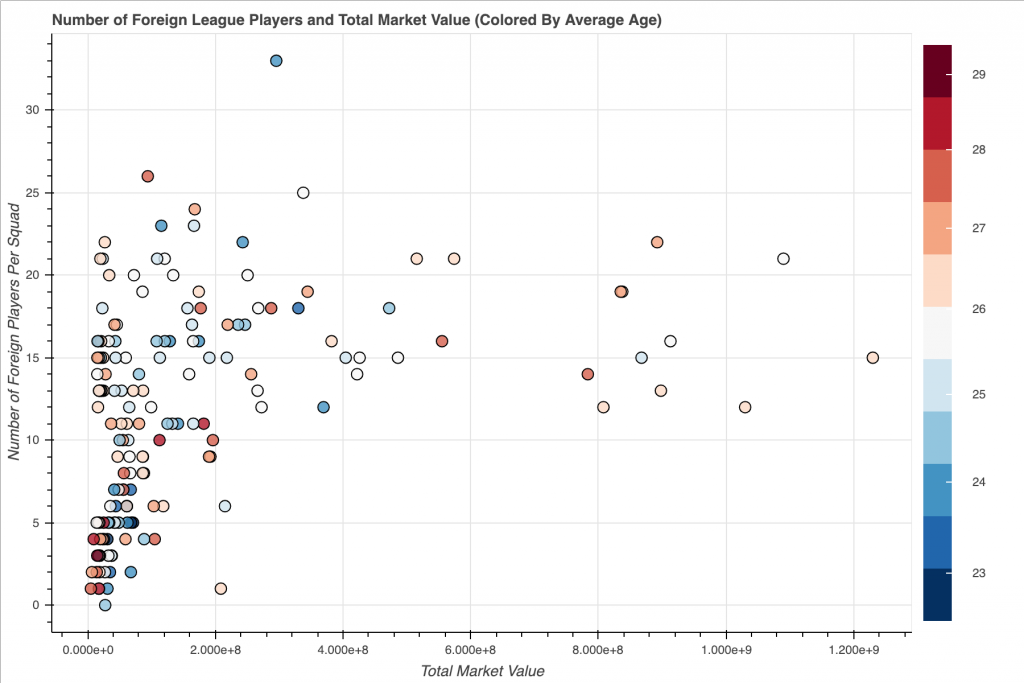
2018 International Football TransferMarket Visualization in Bokeh
The goal of this project is to scrape and crawl through multiple pages of TransferMarket.com and create an interesting Bokeh Visualization. The data was scrapped using BeautifulSoup and compiled into a SQLite database. Then SQL queries were constructed and the query results were loaded into a Pandas to allow for easier data manipulation. Finally, that data was loaded into Bokeh to create a Scatter Plot that explores the relationships between a soccer teams A) Average Squad Age B) 2018 Squad Market Value and C) Number of Foreign Players found in each Squad.
Tidyverse dplyr and ggplot2: How to Manipulate and Visualize Data Easily in R
R is a popular programming language and free software environment for statistical computing and visualization. The language and software is widely used among statisticians and data miners for developing statistical software and data analysis. This tutorial is designed to give the reader a quick start on their journey with R. The intended audience is someone with a basic understanding of data analysis and programming languages. The tutorial is mainly divided into two parts: Data manipulation and visualization. The data manipulation portion explains how to use base R functions and the dplyr package to clean, reformat, subset, and summarize the data in various ways. The visualization portion explains how to use the ggplot2 package to create interesting visualizations of the data that was manipulated. The tutorial clearly explains the common uses of each function by applying them to a focus dataset. Thus, the code from this tutorial can be adapted for data manipulation and visualization for any data set.
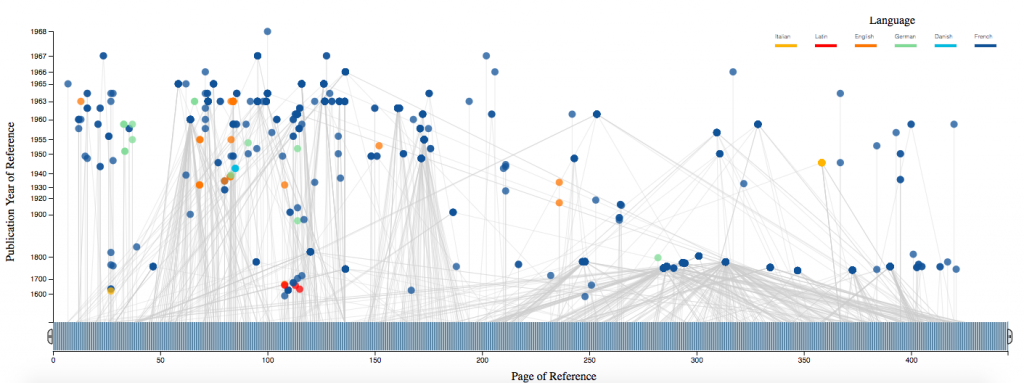
Derrida: Visualization of Derrida’s Margin in D3
Jacques Derrida is one of the major figures of twentieth-century thought, and his library – which bears the traces of decades of close reading – represents a major intellectual archive. The Princeton University Library (PUL) houses Derrida’s Margins, a website and online research tool for the annotations of Jacques Derrida. We used data collected from this project to create visualizations of the references used throughout Derrida’s De la grammatologie.
In this interactive visualization for Derrida’s De la grammatologie we represent each book referenced (nodes) and the locations where each book is referenced in the work (lines connecting nodes to the x-axis). The x-axis represents De la grammatologie from start to finish, and the y-axis represents the years in which each referenced book was published. The color of each node indicates the language in which each referenced book was published, and the position of each node is an averaged position among the pages at which the node was references in De la grammatologie. A brush tool is implemented along the x-axis to select ranges of De la grammatologie and references made within the selected range. By mousing over each node, the book title, author, and publication year are displayed.
This code can be adapted to create an interactive visualization for any data set, either for book references or another type, which includes many entries, an x-axis location for each entry, a y-axis location for each entry, and information to display with the mouse-over feature. The interactive and visual components are most interesting when entries are not discrete, and can be connected with a significant frequency to many locations along the x-axis.
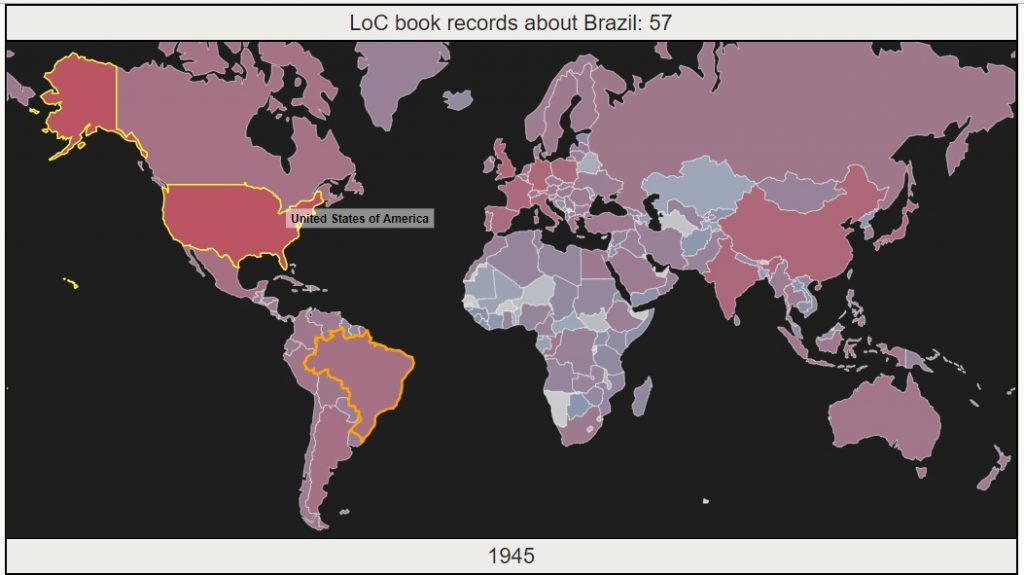
Mapping with D3: Library of Congress books over time
In May 2017, the US Library of Congress made the largest release of digital records in its history – metadata for over 25 million books, maps and recordings. People immediately started making some pretty cool visualizations to explore patterns in the data, or demonstrate the incredible size of the release. This page follows my process of building an animated D3 map visualization, from data cleaning to adding features. Each of the pages below covers one step in the process. Jump to the last page to explore the visualization.
- Preparing the Data – Parse massive xml record files, cache and geocode subject locations, aggregate for our visualization.
- Basic Animation – Build a D3 map that animates changing numbers of records about each country over time.
- Add a Tooltip – Add a tooltip to display country name on hovering. Select a country on click to show record counts for that country.
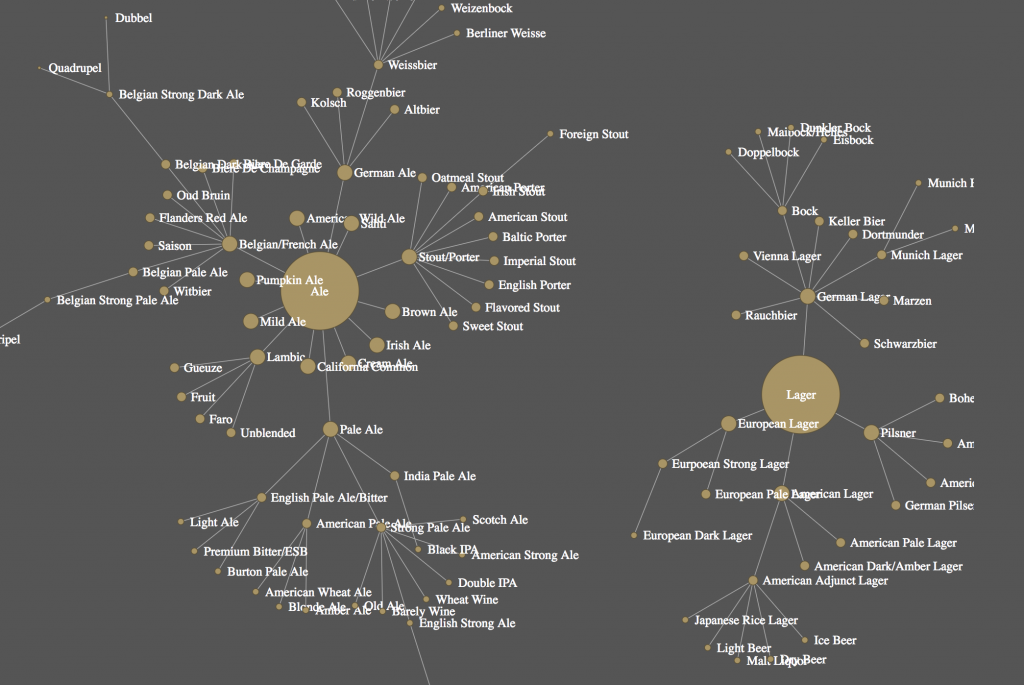
Network Visualization: The relationships between beer
This tutorial will walk through the steps to build an interactive network visualization. The theme we visualize in the example is the web-network of different types of beer and their relationships to each other. The beer visualization illustrates how all beers are related from two common parents: Ales and Lagers.
https://clarkdatalabs.github.io/web_network_visualization/
Using Processing to Visualize Space Exploration
(Read Time: About 3 Min.)
The Challenge:
Could the total distance traveled by a NASA space shuttle have reached Mars? How far did each shuttle go in relation to our solar system? As an inaugural project to get our digital projects studio thinking and managing a project, we used a dataset that recorded the distance traveled by each space shuttle launch from 1981 – 2011 and worked to visualize the total miles traveled for each shuttle as a hypothetical race to the red planet.
Text Mining and Self Organizing Maps: Visualizing Shakespeare
After my previous exploration of Self Organizing Maps, I decided to use the tool for an application of text mining: Can we visualize how Shakespeare’s characters and plays are similar or different from each other based on an analysis of their words?
This tutorial walks through a couple examples using R and suggests some further exploration. It’s split into two sequential parts:
Self Organizing Maps and Text Mining – Visualizing Shakespeare (Part 1)
Self Organizing Maps and Text Mining – Visualizing Shakespeare (Part 2)
From Networks to Scrapbooks: A Case Study of Data Visualization Consulting (Part 2)
Part 2: Writing and Visualizing the Data Narrative
In contrast to the tens of thousands of records associated with the collection as a whole, the Bentley Student Scrapbooks consists of 88 scrapbooks documenting student experiences at the University of Michigan spanning the 1860s to the 1940s, with most scrapbooks falling between about 1906 to 1919. These scrapbooks covered a fascinating cross-section of life on campus – everything from student athletics to cross-dressing to secret societies to dance cards appeared in the Subjects field of the metadata.
When I asked the (admittedly naive) question “what do you mean by scrapbooks?” the archivist team had a lot of stories to share. For instance, I had no idea that a fraternity in 1910 might keep track of their beloved top athlete in painstaking detail and then put it all into a scrapbook for posterity. It was genuinely lovely to experience their enthusiasm about this collection, which often focused on specific backstories to the creation or legacy of these scrapbooks that fell outside the metadata itself. How then, I wondered, might a data visualization narrative support these passionate archivists in their public lectures and workshops? What types of patterns should we focus on revealing? (more…)
From Networks to Scrapbooks: A Case Study of Data Visualization Consulting (Part 1)
Part 1: Finding the Story in Data
Introduction
When you set out to tell a story with data, how do you determine its scope and focus? What kind of relationship do you want to cultivate between your viewers and the data being visualized? If there is a “best” or “most effective” story lurking in the data for the audience at hand, how do you pick it apart from the others?
Data visualization refers to a set of tools and practices, but also a deeper struggle to find a way to craft meaning from representations of reality, and share that meaning with others via narrative. In this post, I’ll explore how I grappled with identifying and framing a data visualization story in the context of a semester-long consulting project with the Bentley Historical Library.
The Bentley
According to the Bentley’s website:
The Bentley Historical Library collects the materials for and promotes the study of the histories of two great, intertwined institutions, the State of Michigan and the University of Michigan. The Library is open without fee to the public, and we welcome researchers regardless of academic or professional affiliation.
The Bentley is home to a massive, diverse trove of items spread across 11,000 collections. When the Bentley reached out to the Digital Project Studio last fall, they had a central goal in mind: helping researchers understand the collections better, and engage with these collections in ways beyond the affordances of simple keyword searches or browsing alphabetical lists. They hoped data visualization could provide something special to spur that process – a new kind of insight or way of interacting. (more…)