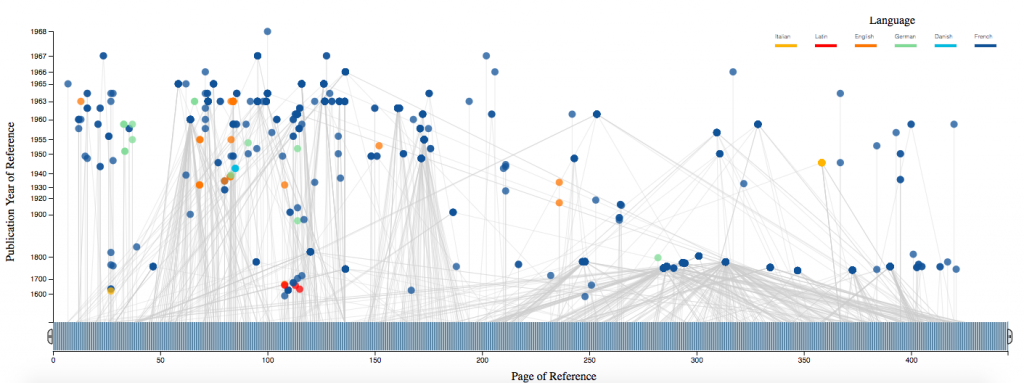
Networks can provide significant measures to identify data driven patterns and dependencies. Though, given a data file it can be difficult to discern how one may approach creating such a network. In this tutorial, we will use a bibliographic data file downloaded from a query search in Scopus to walk through the process of cleaning the data file, writing a python script to parse the data into nodes and edges, computing graphical measures using NetworkX, and creating an interactive network display using HoloViews.
We tried out multiple Python libraries for ease of use and efficiency before landing on this combination. Building a network was more intuitive in NetworkX than iGraph. However, it took several minutes to render our large graph and a interaction was sticky. Pyvis was easy to build a network with and can be expanded to incorporate more advanced NetworkX functionality with only a couply lines of code. However it still took a long time to render, with slow manipulation. Holoviews, which runs on top of the native Python visualization library Bokeh, enables NetworkX to render quickly, with versitile manipulation. The graphs are produced in HTML and JavaScript for easy integration into webpages.
About Colaboratory
While we originally developed this script in a local notebook, we found that running it through Google’s cloud-based Jupyter notebook environment Colaboratory is a smoother option, particularly for nacent coders. We encountered version conflicts between the dependencies when setting up a local notebook environment that were bipassed in Colab. Colaboratory allows you to use and share Jupyter notebooks from your browser, without having to download, install, or run anything on your own computer. Notebooks can be saved to Google Drive, Github or downloaded locally. This code contains OAuth2 functionality to access data from Google Drive, with a link to instructions for access from Github. A single line of code adapts the script render in Colab.
To open the notebook in Colab, click on the notebook from the repository list. GitHub will open a preview, click this icon from the top of the notebook to open directly in Colaboratory. (If the preview doesn’t load, you may have to disable your ad blocker.) Alternatively, you can clone or download this repository and put in Google Drive. Google Drive will recognize the .ipynb notebook file format and give you the option to open in Colaboratory.