
Our Project
Opinions tend to reflect feelings as well as beliefs. Sentiment analysis, also known as opinion mining, is a technique used today for generating data on trends in people’s attitudes and feelings on anything from products and services to current events. This data is created by calculating sentiment scores using what people have said or written. Despite the efforts of computer scientists, semanticists and statisticians to figure out ways to program computers to identify the feelings expressed in words, the technique of sentiment analysis is still at best only reliable as a starting point for closer readings.
The results of sentiment analysis can quickly become misleading if presented without any reference to the actual passages of text that were analyzed. Nevertheless, it is helpful as a technique for delving into large corpora and collections of unstructured texts to capture trends and shifts in sentiment intensity.
For a final collaborative project of the academic year 2015-2016, our team at the Digital Projects Studio decided to take on the challenge of visualizing the intensity of emotions and opinions expressed during the 2016 primary election debates. (Click here to see the final product). Our dataset was a set of complete transcripts for twelve Republican and eight Democratic debates. To process the data, we filtered out interventions of moderators and interjections from the audience, ran the statements of each candidate through a sentiment analyzer from Python’s NLTK (Natural Language ToolKit) library, and indexed the statements of each candidate by debate number, numeric sentiment score, and sentiment category.
Basic Sentiment Analysis: How it works
The initial point of departure for much of current sentiment analysis is based on assigning words into categories of “positive” and “negative”. This approach usually relies on the use of a lexicon. Lexicons are like dictionaries and can be written by human beings or constructed through machine learning. A lexicon contains entries with data about words (or word stems); data entered about a word could include its part(s) of speech, spelling variants, inflectional variants, encoded syntactical information, and so on. There are a variety of sentiment lexicons out there geared specifically towards sentiment analysis.
Our Choice of Sentiment Analyzer
For our sentiment analysis, we chose a sentiment analyzer called VADER (Valence Aware Dictionary for sEntiment Reasoning), which is available with Python’s NLTK library. VADER was designed for analyzing live streams of social media content. The developers of the tool also tested it on “sentence-level snippets” from NYT opinion pieces (Hutto & Gilbert, 2014). VADER interfaces with a lexicon called SentiWordNet, which is an extension of the lexical database WordNet. Hutto and Gilbert used SentiWordNet to calculate the differences between sentiment scores of synsets (groupings of synonyms) to categorize the synsets by the “intensity” of the sentiments each synonym ring conveys. The lexicon that they created is available here on GitHub. For further reading and resources on the design of VADER, there is also Hutto and Gilbert’s overview from the README file for the project on GitHub.
Data Processing and Index
We indexed our data using the Python library Whoosh. We created a schema, which contained every debate intervention (‘sentence’) with the name of the candidate who was speaking and the debate number. We then ran the text of each of the indexed interventions through VADER’s Sentiment Analyzer and added the resulting numeric sentiment score to our index. Finally, we assigned each of the sentiment scores in the index to one of five categories:
‘positive‘ ( score > 0.5);
‘somewhat positive‘ (score < 0.5 and score > 0.1);
‘neutral‘ (score < 0.1 and score > -0.1);
‘somewhat negative‘ (score < -0.1 and score > -0.5);
‘negative‘ (score < -0.5).
Once we had generated our index, we could run quick searches on it for words or phrases of interest. The index would return all relevant interventions containing the search word or phrase, as well as the corresponding sentiment category to which that intervention had been assigned. We wrote a Python script to aggregate counts for each category by candidate and by debate and then return the results in JSON format.
Resulting Search Outputs
Search results have been hit or miss. Below are a few examples of various outputs for different search terms and phrases.
Immigration
The following is an example of a slice of a JSON output for the search term ‘immigration‘. The slice represents one full entry containing all the interventions by Bush concerning immigration in the fourth Republican debate (there was only one).
{
“count”: 1,
“candidate”: “BUSH”,
“sentiment”: “somewhat negative”,
“debate_date”: “11/10/2015”,
“sentences”: [“What a generous man you are. Twelve million illegal immigrants, to send them back, 500,000 a month, is just not — not possible. And it’s not embracing American values. And it would tear communities apart. And it would send a signal that we’re not the kind of country that I know America is.”],
“debate”: “4”
}
The data entry in JSON format above is a fair assessment (in my opinion) of Bush’s intervention in the fourth Republican debate, given the nature of the analysis and sentiment categories. Nevertheless, unless we can access and consider the statement’s context we can’t say much. When we read the text (under ‘sentences’) itself, we can’t say Bush’s attitude towards immigration is ‘negative’ based on this statement. We could agree the feeling behind the statement as a whole is ‘somewhat negative’, as it is indeed the negation of another candidate’s opinion; however, the meaning of the statement itself proves to be a separate issue altogether. Bush is responding negatively to another candidate while speaking ‘positively’ in favor of immigrant asylum here; beyond that, we can’t infer much about Bush’s attitude toward immigration based on this statement alone.
The above example illustrates that we are analyzing the transcripts for sentiment intensity rather than meaning. Our metric for sentiment intensity is structured according to the polarity of positive/negative–we are not accounting for particular states of emotion (for example, anger or sadness) per se. In short, these terms of classification are equivocal, and essentially, the analytic parameters we have in place are paving the way for over-simplication of candidates’ interventions, particularly when these interventions tend to be longer and more complex.
Why are any of the above considerations important? Let’s consider some other examples.
Wall Street
You would assume Bernie Sanders would not have one positive thing to say about Wall Street….Now look at some of the results for ‘Wall Street’:
Sanders in 2nd Democratic Debate:
“positive”: 6,
“somewhat negative”: 2,
“negative”: 1,
“somewhat positive”: 1
Sanders in 8th Democratic Debate:
“positive”: 3,
“somewhat negative”: 4,
“neutral”: 1,
“somewhat positive”: 6,
“negative”: 1
Debates 1 and 3 seem more on point….
Sanders in 1st Democratic Debate:
“positive”: 3,
“somewhat negative”: 1,
“neutral”: 1,
“somewhat positive”: 1,
“negative”: 4
Sanders in 3rd Democratic Debate:
“positive”: 2,
“neutral”: 1,
“negative”: 5,
“somewhat positive”: 1
Let’s look at some of these “positive” statements by Sanders about Wall Street:
- “Yes, I do believe there must be a tax on Wall Street speculation. We bailed out Wall Street. It’s their time to bail out the middle class, help our kids be able to go to college tuition-free.” (Sanders, Debate 2)
- “In terms of Wall Street, I respectfully disagree with you, madam secretary, in the sense that the issue here is when you have such incredible power and such incredible wealth. When you have Wall Street spending $5 billion over a 10-year period to get — to get deregulated, the only answer they know is break them up, reestablish Glass-Stegall.” (Sanders, Debate 2)
- “Well, you’ve got to look at what the career is about. And this is a career that has stood up to every special interest in this country. I don’t take money from Wall Street. I demand that we break up the large financial institutions.” (Sanders, Debate 8)
- “Is it acceptable that Wall Street and billionaires are spending hundreds of millions of dollars trying to buy elections? Is that democracy or this that oligarchy? Which is why I believe we’ve got to overturn Citizens United and move to public funding of elections.” (Sanders, Debate 8)
These sample statements are all longer than one sentence and longer than tweets of 140 characters or less, rendering these interventions more complex than shorter statements. They also contain a variety of ‘good’ words that apparently cumulatively helped tip the scale toward “positive”. Example 1 includes positive words like “help” and “free” (in tuition-free); Example 2 contains “respect”, “incredible wealth” , and “incredible power” (the adjective “incredible” is likely boosting the “positive” weight accorded to “wealth” and “power”); Example 3 has “special” and “interest”; Example 4 contains positive words like “acceptable” and “democracy”. Apart from the words, these sentences are affirmative in nature. Sanders is either affirming facts or affirming his own ideas, but the subject is still Wall Street. What we see happening here is in fact similar to what we say with the example of Bush’s intervention on immigration, except here Sanders is affirming, whereas Bush was negating.
Since these examples are looking at particular results, isolated from the rest of the results returned for a search term, we could also consider a set of results from a higher level as a cohesive whole. What are the quantities of positive, negative, and neutral statements telling us about candidates’ attitudes when taken together as a whole? What kind of representation of candidates’ attitudes are these numbers providing? What kinds of inferences can we allow (or not allow) ourselves to draw from this data?
ISIS and Terrorism
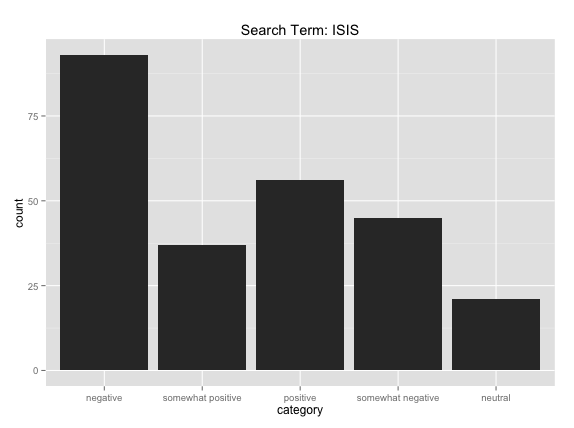
Let’s consider all the statements made about ISIS over the course of all eighteen debates. ‘ISIS’ is a term that you would think would not return very many positive scores, if any, or you would think that the total negative counts would far outweigh the positives and somewhat positives. When we run the search script and ask Python to count the total statements and report the number of statements in each sentiment category, we find this is not the case:
252 statements
“Positive” count equals 56
“Somewhat positive” count equals 37
“Neutral” count equals 21
“Somewhat negative” count equals 45
“Negative” count equals 93
“Positive” and “somewhat positive” add up to 93, which equals the exact count of “negative” statements (though “negative” and “somewhat negative” taken together is 138). Below is a bar graph showing these same results:
However, if we run a search on “terrorism” we get the following results:
86 statements
“Positive” count equals 7
“Somewhat positive” count equals 8
“Neutral” count equals 7
“Somewhat negative” count equals 9
“Negative” count equals 55
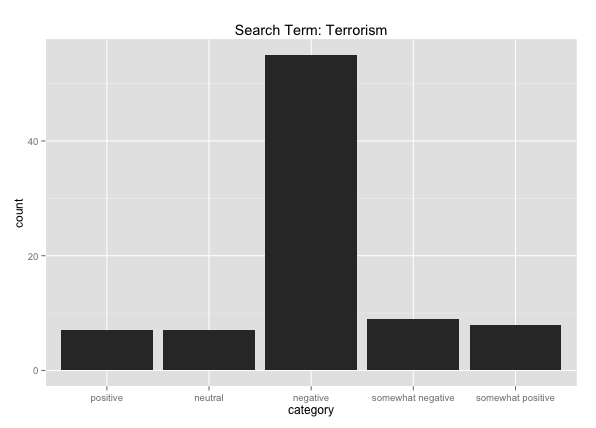
The aggregate results for “terrorism” yield a visualization showing much more what one would expect to see from the candidates with regard to this topic, with the count for “negative” significantly surpassing all other categories. ISIS, on the other hand, returns more of a mixed result. There may be a simple reason for this. “Terror” and “terrorism” are in the VADER lexicon and have been pre-assigned negative scores. When you search for a “negative” word, you are guaranteed a lot of negative results, not only because the search term is negative, but also because it’s more likely to appear alongside other words belonging to negative synsets. “ISIS” on the other hand, isn’t in the VADER lexicon.
We can again look at some specific samples from the “positive” and “somewhat positive” results for the search term “ISIS”:
Positive:
“Right. What we have got to do there is, among other things, as I was just saying, have Silicon Valley help us to make sure that information being transmitted through the Internet or in other ways by ISIS is, in fact, discovered.” (Sanders, Debate 4)
Somewhat positive:
I think the president is trying very hard to thread a tough needle here, and that is to support those people who are against Assad, against ISIS, without getting us on the ground there, and that’s the direction I believe we should have (inaudible). (Sanders, Debate 1)
To honor the people that died, we need to — we need to — stop the — Iran agreement, for sure, because the Iranian mullahs have their blood on their hands, and we need to take out ISIS with every tool at our disposal. (Bush, Debate 1 )
Similarly to the prior examples with Sanders’ “positive” remarks about Wall Street, these snippets contain a fair number of words that can be seen as positive by themselves. These statements contain positive words like “help”, “support”, and “honor”. The “honor” in Bush’s statement from debate 1 may have been tempered by a negative term like “died”, but the final effect of the computer’s calculations could be said to be not entirely inaccurate here. If anything, the calculations are helpful as an initial classification before launching into a deeper reading of specific parts of the debates.
The positive statement by Sanders from debate 4 has even arguably been accurately classified, because the meaning behind the statement isn’t really about ISIS alone, it’s about how to track communications of among members of ISIS with the help of tech experts. Although I did assert earlier that we are using VADER to analyze sentiment intensity and not meaning, the fact still remains that sentiment will naturally follow from meaning, although when using this tool, I would argue it’s best to consider the sentiment and meaning as distinct from one another. We could never guess the meaning of Sanders’ statement if we only had the statement’s sentiment rating. There would be too many possibilities. The only way to avoid drawing false conclusions about the “positive” tone of Sanders’ intervention is to retrieve the text of the statement itself. Sometimes, even this may not be enough–we might want to read more around the statement, get more more context, and see the other statements to which he was responding.
Conclusion and Questions of “Neutrality”
Our search and visualization tool can finally be said to serve as a kind of classification tool, which classifies statements by sentiment (with a fair level of accuracy). While sentiment is tied to meaning, our exploration of the tool’s capabilities shows that it is useful for getting a sense of the attitudes being expressed at a given moment in the debates, but not necessarily the attitudes towards the subject which the user searched. The search function results in the retrieval of all statements in which the subject term and any related terms with the same stem are mentioned. The attitude expressed, however, as in the case of the “ISIS” example, may not be the result of that term’s presence in the statement.
In addition, the sentiment analyzer, as it reads and computes statements word by word, may skew the sentiment analysis or produce a number that is arguably accurate but makes little sense to us outside of the context of the original text. A positive score for a statement where “terrorism” is mentioned is an example of this. On the one hand, the analyzer is in some sense less ‘biased’ than a human reader, who may zero in on certain words and give them more weight than others…it adds up all the word-stems it knows and impartially weighs them against each each other on a positive-negative scale. This may not always result in an accurate reading, however, as we saw in the example of Bernie Sanders’ positive statements with regard to Wall Street. The machine still does not have the judgment of a human reader, who has the ability to decide which words should be given more weight when and why depending on context.
With this in mind, our tool has a feature which allows users to hover over the graph and view the original text corresponding to the scores which the stream-graphs represent. If users need more context, they can identify the debate by date and search the sentence in the original transcripts to read more of the original context. If you haven’t already tried it out for yourself, we invite you to explore the tool here.
Moving forward, considering what makes a statement “neutral” would a valuable question to pursue. “Neutral” statements are intended to be understood as fact — the neutral outputs returned by computers are often not factual. Take the following example of Bush’s statement:
Serious times require strong leadership, that’s what at stake right now. Regarding national security, we need to restore the defense cuts of Barack Obama to rebuild our military, to destroy ISIS before it destroys us. Regarding economic security, we need to take power and money away from Washington D.C. and empower American families so that they can rise up again. (BUSH, Debate 5, neutral)
Most human readers would probably interpret an excerpt like this as more reflective of Bush’s opinions as a candidate rather than a report of the facts. In light of this, we could ask, does the length of the text impact the likelihood that an analyzer like VADER will rate the snippet as “neutral” as opposed to more strongly positive or negative? Better understanding the mechanism at work in a tool like VADER might help with working towards designing analyzers and applications equipped to breakdown and handle longer and more nuanced passages of text.