
Introduction
The aim of this blogpost is for a beginner level user to be able to scrap data from Twitter. In this example, I’ll scrap the 20 most recent statuses from @PureMichigan‘s Twitter feed. My end goal of scraping these posts is to find out quickly who has been talking about @PureMichigan on Twitter most recently and what they are saying. You can also use the count feature to pull up to 200 statuses at a time and analyze the content.
Here’s a screenshot of what you’ll get at the end:
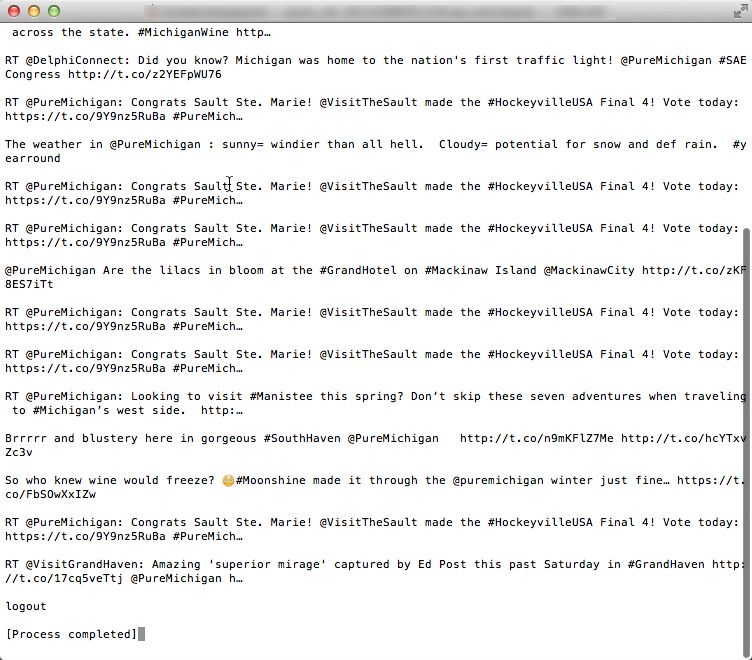
Previous Knowledge Required:
- How to access Terminal on a Mac or Command Prompt on Windows
- If you have a Mac check out this video to learn more
- If you have Windows 8 check out this video to learn more
- This post shows how to open the command prompt for pre-Windows 8 systems
- How to run the command line
- Don’t worry once you have terminal open you can copy and paste the code below
- Have Python downloaded on your computer
- Macs usually already have Python installed. If you don’t have Python you can download it here regardless of your operating system.
- I recommend version 2.7
Steps to Setting Up Scraping
- Create a Twitter App here by signing into your Twitter account and following the instructions on the screen.
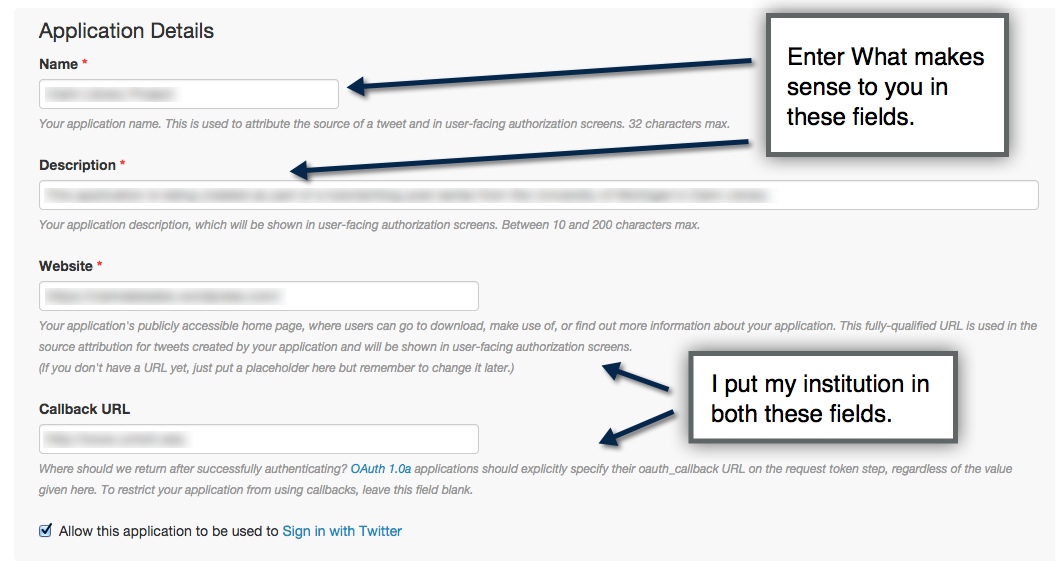
- Create your API Token. Generating the Token may take a second. Just refresh the page for the Token to appear.
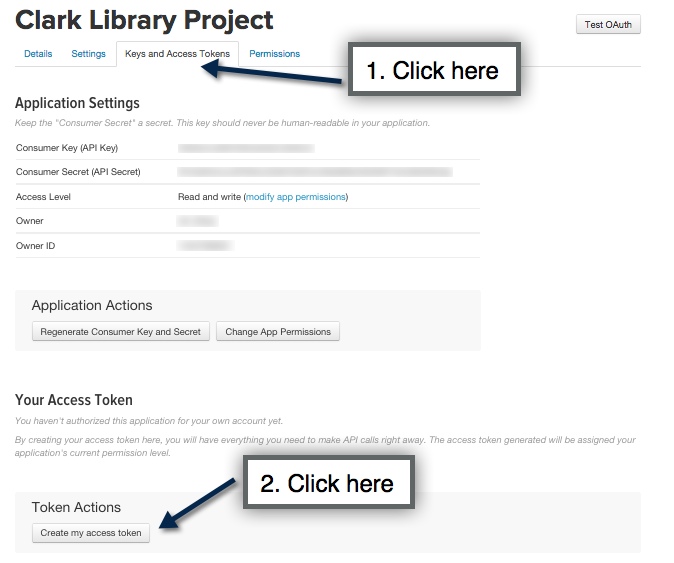
- We’re done with Twitter for the moment but keep the window with your token information open. It’s time to install the Twython package to help you read and scrape the data from Twitter. You can do this by opening up your computer’s Terminal (or Command Prompt), and copy and pasting the following lines of code:
pip install Twython
After typing in a line you’ll want to wait until you see a line that says, “Successfully installed Twython“.
All of these are Python Libraries. A library in Python is a bunch of pre-written code that someone has been kind enough to give you for free and it’s safe to use/install.
Scrape the Status data
Copy and paste everything in italicized into your favorite Text Editor (i.e. Sublime, TextWrangler, Notepad++, etc). I recommend using TextWrangler for this example because it is easy to quickly run the code in Terminal without having to run the command line:
LIBRARIES OF USE
import sys
import string
from twython import Twython
PROVIDING AUTHORIZATION
twitter = Twython(‘Insert Your Consumer Key Here‘,
‘Insert Your Consumer Secret Key Here‘,oauth_version=2)
Access_token = twitter.obtain_access_token()
t = Twython(‘Insert Your Consumer Key Here‘, access_token=Access_token)
All the “Key” information is located on the page where you created your Twitter API token.
Setting up what data you want and how much
user_timeline = t.search(q=’@puremichigan’, count=20, include_rts=1)
- You can replace ‘@puremichigan’ with your own Twitter page where you want to scrape the data.
- The count is the number of Tweet statuses you want to get back. 200 is the max at one time.
- “include_rts =1” means that you want to include retweets in the data. If you don’t want retweets you can delete this part.
Getting the Tweets
for tweets in user_timeline[‘statuses’]:
print tweets[‘text’] + “n”
This part pulls all the Twitter statuses out of the API for the screen name you specified and prints them out, each on a new line (“n”).
Run The Code in Terminal / Command Prompt
If you copy and pasted all this code into TextWrangler getting the results will be very easy. Take a look at the screen shot.
First remember to save your file, for example, “Twitter_Statuses.py” and then follow the steps below:
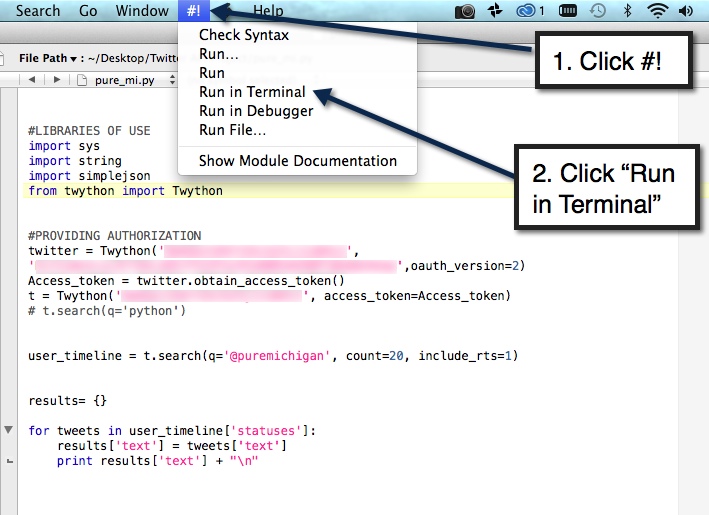
Following the step above should produce a result as seen below that you can copy and paste into your desired type of file.

In Sum, Here’s all the code You’ll Need to Copy & Paste
import sys
import string
from twython import Twython
twitter = Twython('Insert Consumer Key Here',
'Insert Consumer Secret Key',oauth_version=2)
Access_token = twitter.obtain_access_token()
t = Twython('Insert Consumer Key', access_token=Access_token)
user_timeline = t.search(q='@puremichigan', count=20, include_rts=1)
for tweets in user_timeline['statuses']:
print tweets['text'] +"\n"If you’re Interested in Learning More Check out these Sources:
Get Information from Twitter Based on a Twitter ID list
Getting Twitter Data and Using an SQLite Database
Learn the Basics of the Twitter API with Code Academy
For InSpiration Check out:
Visualizations from Twitter done using the Twitter API
One thought on “Getting Started: Scraping Twitter Data”