

The process of Visualizing Twitter status data can be informative and revealing about connections to your brand or any topic that you might not have known existed. For example, when I was going through the Pure Michigan data to make the visual, I had to choose what to include and what to exclude. I kept coming across the word ‘xe2’ over and over in the data. After some digging, I discovered that there were several photographers that were using the new Fujifilm XE2 camera to photograph Michigan’s natural beauty and tweeting at Pure Michigan in the process.
The steps in this post can help you visualize your Twitter status data for any topic or hashtag using Wordle (Note: Does not work on most recent version of Chrome, so I used Safari). You’ve already done the hard work if you’ve scraped the data from Twitter as described in a previous post. When you’re finished with this post you’ll have a visual that might look something like the visual above or below. An advantage to Wordle is that there’s different ways to customize to create fun and informative visuals.

Let’s get started!
Step 1: Install Anaconda
The code we’ll use below “Tokenizes” the Twitter data. “Tokenizing” is a method used by Natural Language ToolKit (NLTK). The toolkit is the leading platform for building Python programs that work with human language data. You can do a lot with NLTK as described here, and we’ll use the toolkit to “Tokenize” the scraped Twitter data and put it into a format readable by Wordle.
Using NLTK requires several different libraries such as numpy, panda, zlib, matplotlib, etc. Instead of having to install all these libraries, save yourself a headache and just install Anaconda. Anaconda is a package of libraries that includes some of the most popular libraries you’ll need to analyze data. By installing Anaconda you’ll install the libraries this post will use in one step. Download the package here.
Step 2: Install Java
Wordle uses Java to create the visualization. You’ll need to download Java version 1.8 or later to utilize some tools developed for NLTK so I recommend just doing it now. Java can be downloaded here. If you run into any issues there are directions on how to install Java here as well.
If you already have Java installed you can check that it’s properly installed here. If Java is properly installed then you’ll be able to use Wordle.
*Note: If you’re having trouble with the Java verification step of proper installation above, try a different browser. Google Chrome may not work as Chrome disabled the standard way it supports browser support plugins starting with the Version 42 release in April 2015.
Step 3: Scrape Twitter data
I adjusted the code from the previous post slightly. You can still follow the steps on on how to scrape Twitter data from this post and the updated code is below. Open your favorite text editor, save the file as a .py (Python file) and run the code to get the twitter status data or hashtag data you’re looking for. Remember that with this method only 200 posts can be pulled at one time. I actually made a note in my calendar each day to scrap data from several weeks when I created my Wordle below. I just pasted the data from each day into the same text file.

Here’s the GitHub code to copy and paste into the file:
import sys
import string
from twython import Twython
twitter = Twython('Insert Consumer Key Here',
'Insert Consumer Secret Key',oauth_version=2)
Access_token = twitter.obtain_access_token()
t = Twython('Insert Consumer Key', access_token=Access_token)
#MAKE THE QUERY TO TWITTER TO PULL THE DATA
user_timeline = t.search(q='@puremichigan', count=200)
for tweets in user_timeline['statuses']:
print tweets['text']+' | 'Remember to save it!
Step 4: Put Twitter Status Data in one File
After following the steps on how to scrape Twitter data (see this post for steps), you’ll need to make sure all the statuses are placed in one file. Open your favorite text editor and call the file ‘Statuses.txt‘. This is important because that’s the name of the file the code below will call to get it into the right format.
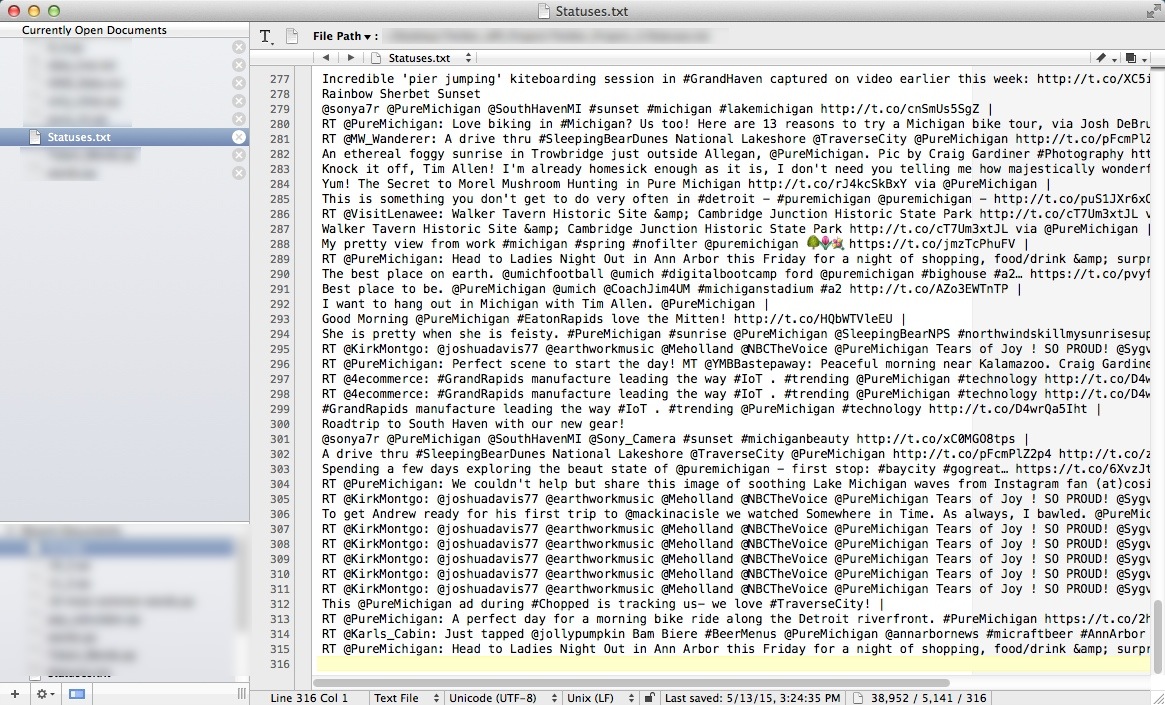
Step 5: The Code
Open a new file in the Text Editor and save the file (as a ‘insert_any_name_here.py’). Make sure to save the file to the same folder as your Status.txt file. If you don’t the code won’t run correctly. Next, copy and paste the following code into your new Python file and save it.
from __future__ import division
import nltk
import re
import pprint
from nltk import word_tokenize
from nltk.tokenize import RegexpTokenizer
import numpy as np
tokenizer = RegexpTokenizer(r'\w+') #this is important because it takes out the punctuation that Python can't read
f= open('Statuses.txt').read() # open the file
# number = re.search(r'\d+', f).group()
# print number
statuses = f.split(' | ')
exclude_words=["http", "rt", "co", "in", "of", "is", "you", "me", "my", "mine", "to", "the", "i", "them", "so", "t", "by", "?", "it",
"so", "continue", "will", "probably", "was", "one", "two", "aboard", "about", "above", "across", "after", "against",
"along", "amid", "among", "anti", "around" "as", "at", "before", "behind", "below", "beneath", "beside", "besides",
"between", "btw", "beyond", "but", "by", "concerning", "considering", "despite", "down", "during", "except", "excepting",
"excluding", "following", "for", "from", "in", "inside", "into", "like", "minus", "near", "of", "off", "on", "onto",
"opposite", "outside", "over", "past", "per", "plus", "regarding", "round", "since", "than", "through", "to", "toward",
"towards", "under", "underneath", "unlike", "until", "up", "upon", "versus", "via", "with", "within", "without", "?",
"!", "?", "out", "it", "as", "when", "will", "not", "probably", "was", "have", "has", "this", "that", "a", "for",
"htt", "https", "many", "we", "st", "if", "ok", "okay", "all", "and", "just", "did", "amp", "what", "your", "or", "either",
"k", "ain", "ain't", "here", "are", "there", "their", "htt?", "need", "basically", "way", "why", "who", "thru",
"can", "be", "get", "today", "guy", "day", "help", "time", "tomorrow", "tonight", "now", "try", "please"]
for status in statuses: #this tokenizes each sentence individually
tokens = tokenizer.tokenize(status) #create "tokens" out of statuses
words = [w.lower() for w in tokens] #make everything lower case
sentence = sorted(set(words)) #sort all the words in alphabetical order
for exclude in exclude_words:
for s in sentence: #This gets rid of all the small, unimportant connector words in the Tweets
if s==exclude:
sentence.remove(exclude)
filter (lambda x: '\\' in s, sentence)
if len(s) <= 2: #Gets rid of all the one and two letter words
sentence.remove(s)
for wordle_words in sentence:
number = any(char.isdigit() for char in wordle_words) #This gets rid of all the numbers from urls that were split up and from screen names
if number:
continue
else:
print wordle_words #This gives you the final list to copy and paste into WordleYou might notice that there’s an array called exclude_words. These are words that will be taken out of the Twitter status data. If there’s a word you’d like to keep then delete it from the array. If there’s a word you’d like to add, make sure to keep the syntax the same (i.e. “insert_word_here”). This will help with the initial Wordle clean up although Wordle will also get rid of “common” words to leave you with mostly nouns.

Once you’ve finished including/excluding words go ahead and run the code in Terminal. You should get an output that looks something like this:

Copy this set of words, we’ll paste them in the next step.
Step 6: Creating a Wordle
Open a window on a non-Chrome browser (Wordle doesn’t work with Chrome since the new update) and go to Wordle.net. Click on create.

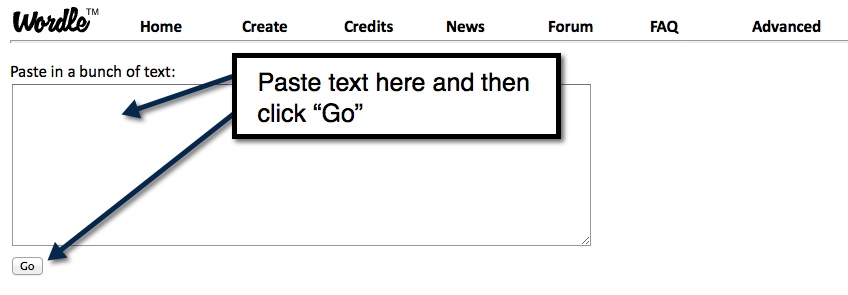
You should get something similar to this:

Since we scraped data from “@puremichigan” that handle will be the largest, which can look cool but makes a lot of the smaller text unreadable. Also you might spot some words that the “exclude_words” step above didn’t catch. To get rid of any word right click on the word and choose delete:

While deleting words you can also customize how the Wordle looks:
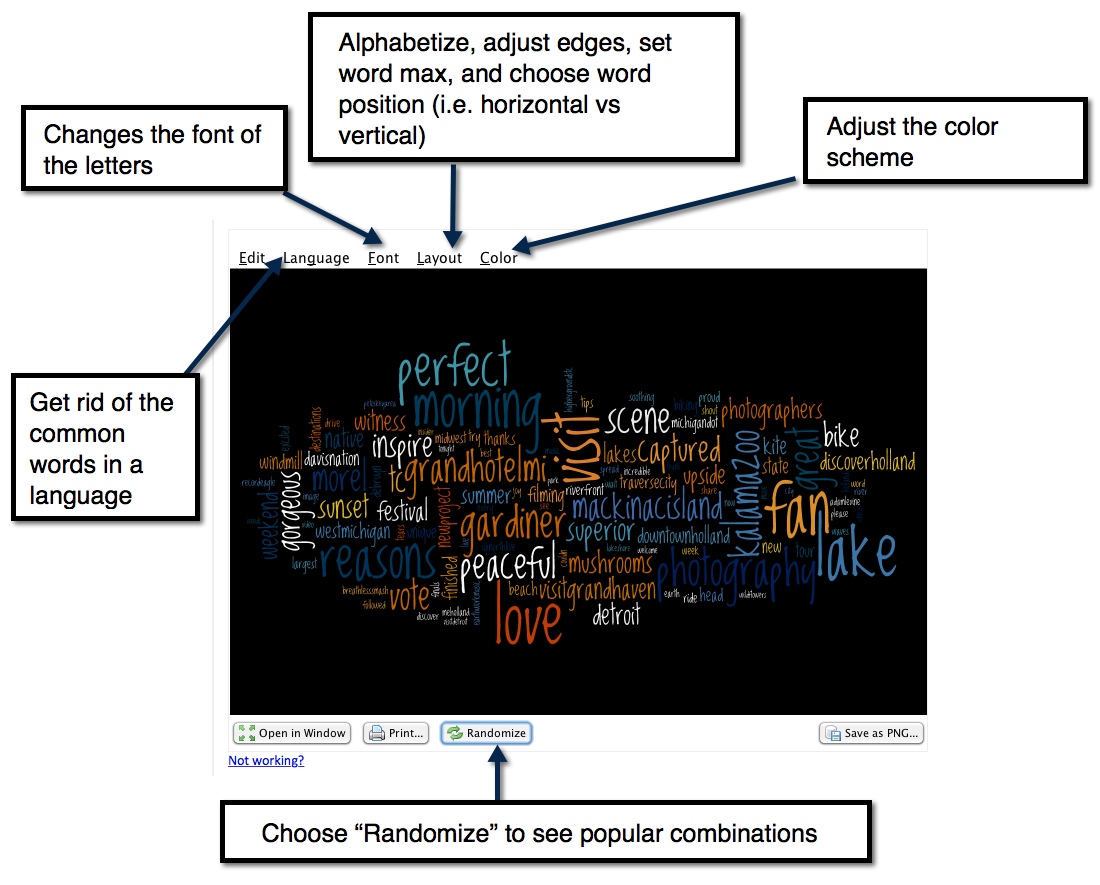
And that’s it!
You should be able to create a beautiful, informative Wordle for your next presentation, discovering new ties to a topic, or to add a new visual to your website.
